AIも忖度するか?
実際、これらの生成AIの要約はどう解釈されるだろうか。今回、オンラインモニターに各AI要約を読んでもらい、内容の信用度を1:信用できない~5:信用できるまでの5段階で評価してもらった。加えて、AI同士でもまったく同じことを行い、その結果をまとめてみた(表2)。ちなみに、評価の際には、「どのAIが生成した要約」であるか、AI名を示した上で評価してもらった。
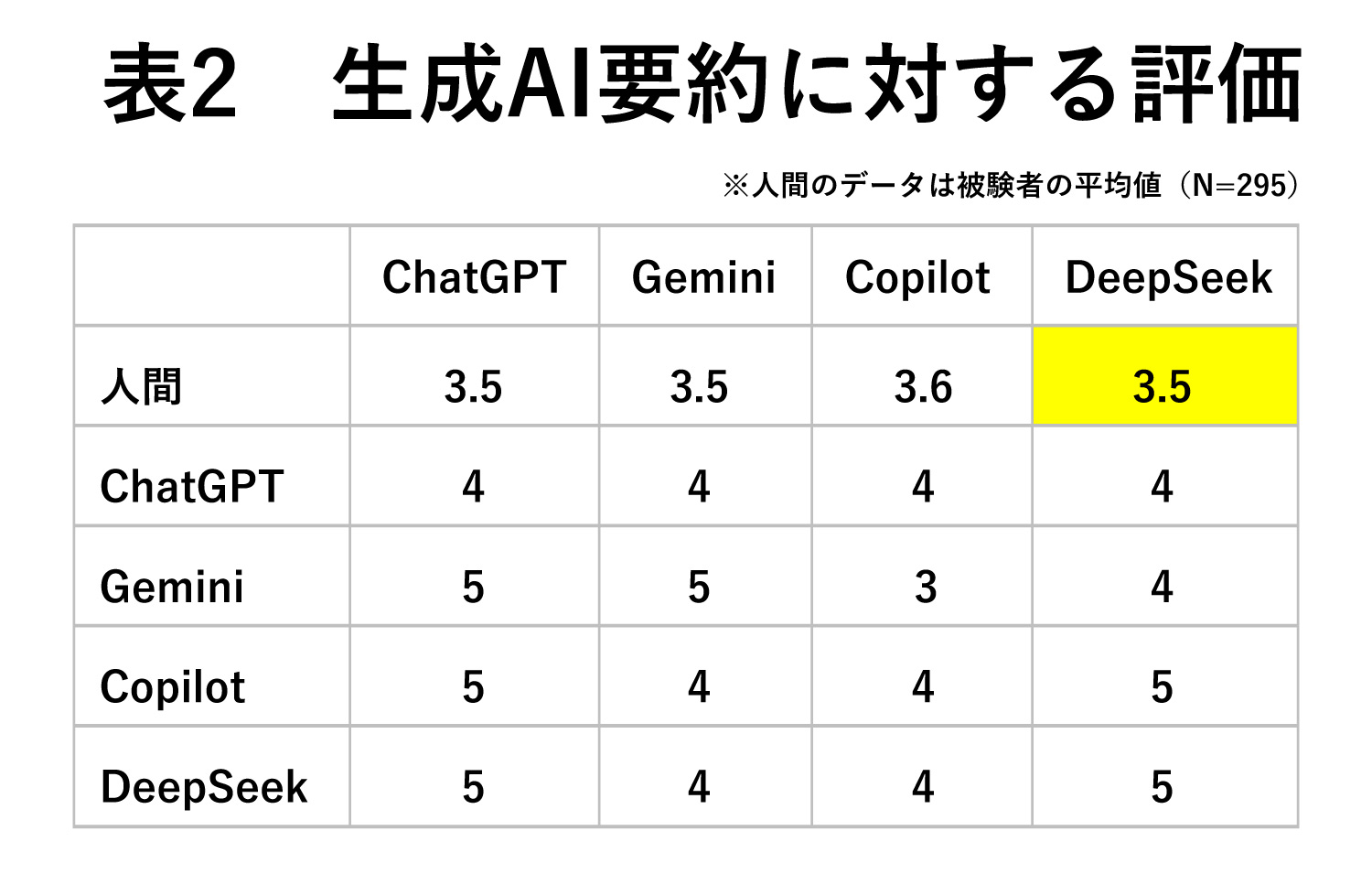
結果をみると、文字数が少ないCopilotの評価が全体的に低く、情報量に依存した評価と言えるかもしれない。ただし文字数ボリュームはDeepSeekに及ばない中、ChatGPTの評価が全般に高かった。
こうしてみると、なんとなく各AIの評価の特徴を感じられる。たとえば、自分自身への評価が高いGemini、DeepSeekがある一方、すべての記述に対して均一的な評価を下しているChatGPTといった対比である。
もちろん、筆者の思い込みや錯覚かもしれないが、不思議なものである。ちなみに、AI同士の評価は、環境面での条件を変えたりしながら複数回試行してみたが、おおむね上記の評価に落ち着くため、AIごとに何らかの評価のアルゴリズムがあるのだろう。
さらに今度は、どのAIによる要約かは教示せずに、「ある生成AIが出した要約です」としたグループを設け(人間のN=283。先の条件とは異なるサンプル)、その評価も記録した(表3)。こうすることで、ChatGPTやDeepSeekなどの固有名詞が「提示された場合(表2)」と「隠された場合(表3)」で、読み手が受ける印象がどう違うかを明らかにできる。
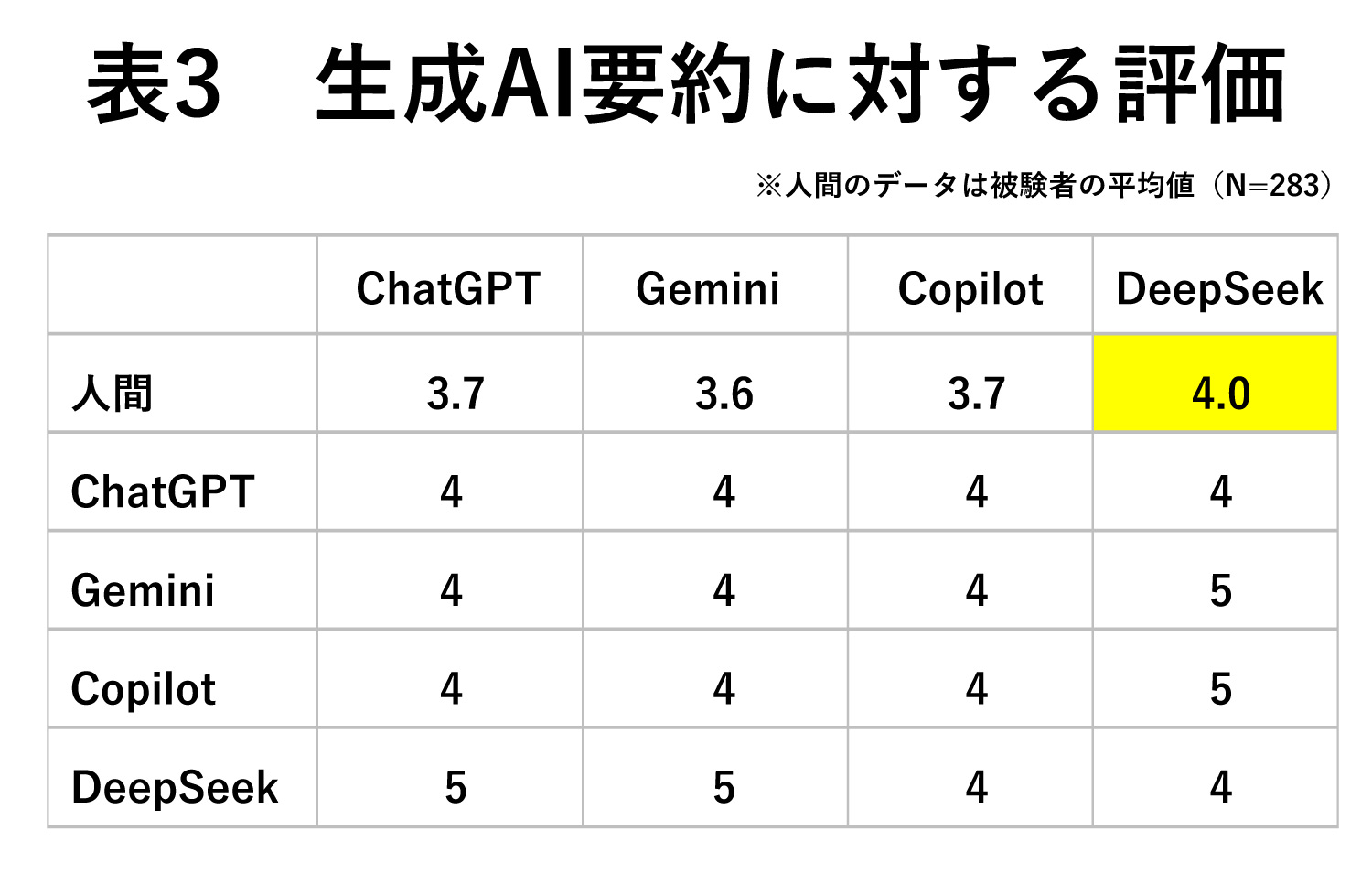
これをみると、人間の場合、同じ要約を読んでいても、AIの固有名詞を教示した場合とそうでない場合では、評価が異なっている。特にDeepSeekについては、DeepSeekの要約であることを明示するほうが読み手の信用度が低くなっている。これは、DeepSeekの開発国である中国に対する読み手の印象や先入観などが、内容評価や解釈に影響したものと考えられる。















